



Explore key Load Balancing Strategies to fix uneven load distribution in high-traffic systems and ensure stability, scalability, and faster performance. Gain full visibility into your workloads and eliminate uneven traffic distribution with smart cloud management practices.
High-traffic systems form the backbone of today’s digital services, powering everything from e-commerce websites to streaming platforms and financial applications. As user activity grows, these systems must handle massive volumes of requests within milliseconds. A well-distributed load ensures every server or service node carries a fair share of traffic, keeping the application fast and stable.
However, when requests begin to pile up unevenly on certain servers or partitions, performance issues emerge. Some servers run hot while others remain underused, leading to slower response times, system lag, or even crashes. This challenge is known as uneven load distribution, and it’s one of the most common performance bottlenecks in scalable infrastructures.
Today, we’ll explore what causes uneven load distribution, how it affects high-traffic systems, and practical strategies to detect and fix it.
Overview
How Load Distribution Works
In a distributed system, workload is shared among multiple servers, services, or partitions. The goal is to process incoming requests efficiently so that no single component becomes overwhelmed. This process is typically managed through load balancing. This is a method of routing requests across several backend nodes.
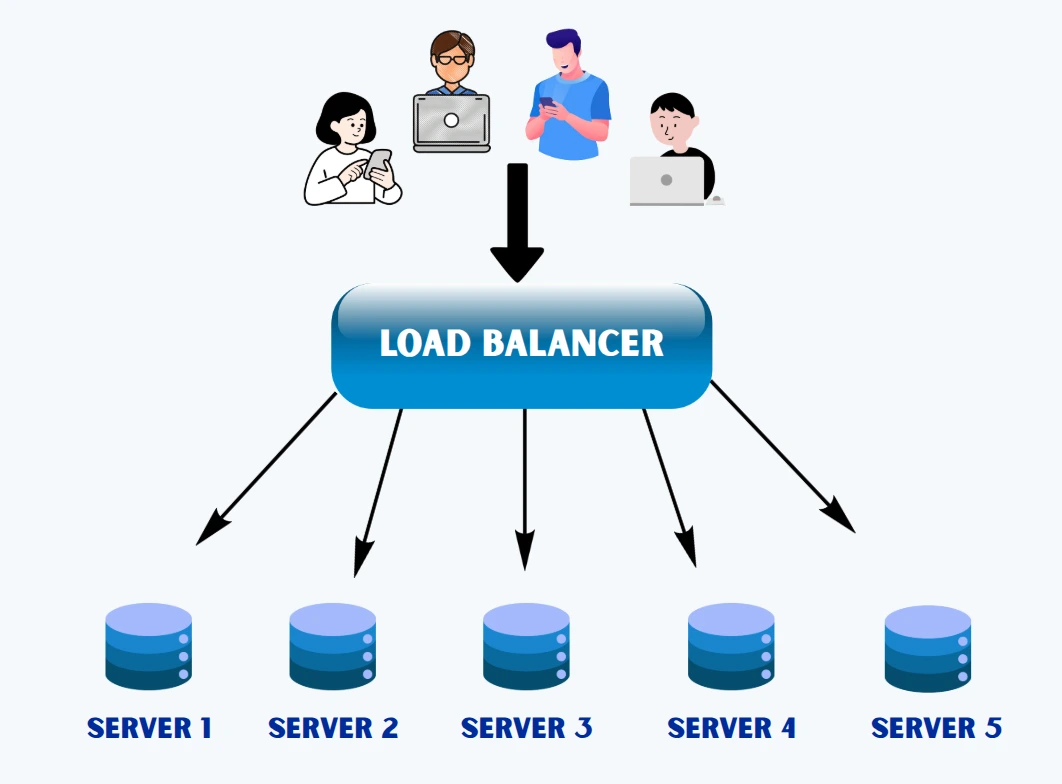
A load balancer sits between clients and servers, deciding which server should handle each request. This prevents overload on any single machine and keeps the system available even when one or more servers fail. Load balancers can operate at different levels of the OSI model, such as:
- Layer 4 (Transport Level):
Balancing based on IP address and TCP/UDP ports.
- Layer 7 (Application Level):
Balancing based on application data like URLs or HTTP headers.
In short, a load balancer ensures that all servers share the load evenly, allowing for scalability and reliability. Yet, in practice, imbalances still occur due to various configurations or performance issues.
Causes Behind Uneven Load Distribution
Even the most advanced infrastructure can face traffic imbalance. Here are some of the most common reasons:
1. Sticky Sessions
Some load balancers use session persistence or sticky sessions to send all requests from the same user to the same server. While this helps maintain session data consistency, it can create an imbalance if certain users generate more traffic than others. A few highly active users can overwhelm one server while others remain underutilized.
2. Unequal Server Capacity
Not all servers are created equal. In cloud or hybrid environments, instances may vary in CPU, memory, or network performance. If the load balancer isn’t aware of these differences, it might assign equal traffic to all servers, causing slower instances to lag behind.
3. Improper Load Balancer Configuration
Incorrect configuration of routing rules or connection limits can distort how requests are distributed. For instance, if certain ports or endpoints are prioritized, some servers might receive a disproportionate number of requests.
4. Lack of Auto-Scaling
Traffic often fluctuates throughout the day. Systems that don’t adjust server capacity dynamically risk becoming overloaded during peak hours. Without auto-scaling, available servers struggle under pressure while others remain idle during low-traffic periods.
5. Application-Level Bottlenecks
Sometimes, an imbalance arises not from the load balancer but from within the application. Services such as message queues, databases, or API endpoints can process requests at different speeds, leading to uneven workloads across components.
Turn Load Balancing into a Strength

The Impact of Uneven Load Distribution
Uneven load distribution affects performance and business outcomes. Some common consequences include:
- Overloaded servers respond late, degrading user experience.
- Underused servers continue running but provide little output.
- Persistent overloads may cause memory exhaustion or process failure.
- In stream or event-driven systems, backlogs can delay message handling or analytics.
- Downtime or lag leads to lost trust and potential revenue loss.
To prevent these issues, teams must adopt proactive monitoring and smart load management strategies.
Smart Ways to Tackle Load Imbalance
1. Review and Adjust Load Balancer Settings
Start by examining how the load balancer is configured. Check if sticky sessions are active and evaluate if they’re truly necessary. For applications that require session persistence (like shopping carts), consider external session stores.
For example:
A team managing an e-commerce platform discovered that sticky sessions were directing all returning users to the same servers. This caused certain nodes to handle significantly more traffic. Disabling sticky sessions and introducing distributed session storage through Redis allowed sessions to be shared across multiple servers. As a result, users were redirected efficiently while maintaining session integrity.
2. Enable Auto-Scaling
Modern cloud environments offer automatic scaling based on predefined performance metrics. With auto-scaling, new server instances spin up when traffic spikes, and unused ones shut down during low demand.
This approach keeps performance stable and cost-efficient. It also ensures that no single server carries more load than it should. Auto-scaling is particularly effective in event-driven or seasonal workloads, where traffic patterns change unpredictably.
3. Implement Lag-Aware Processing
In message-driven architectures like Apache Kafka, uneven load often appears as lag. Some partitions accumulate more unprocessed messages than others. To address this, developers can implement lag-aware producers and consumers.
Lag-Aware Producers track the difference between produced and consumed messages for each partition. If one partition has a large backlog, the producer temporarily slows message delivery to that partition while continuing to send messages to less-burdened ones.
This ensures balanced workload distribution and prevents certain consumers from being overwhelmed.
Lag-Aware Consumers monitor their own lag levels and dynamically rebalance their partition assignments. If a consumer detects that it’s falling behind, it can hand off some partitions to faster consumers.
Together, lag-aware producers and consumers keep data processing consistent, reduce latency, and minimize the risk of data pileups during traffic surges.
4. Apply the Same-Queue Length Algorithm
Another technique for systems using message queues is the Same-Queue Length Algorithm. This method ensures that all queues or partitions maintain similar backlog levels by continuously adjusting message allocation.
Producers monitor the queue length of each partition and redirect traffic to the least loaded ones. This keeps the workload even across the system and avoids bottlenecks that delay processing.
This is particularly useful in systems handling financial transactions or fraud detection, where delays could lead to serious consequences.
5. Use Weighted Load Balancing
When server capabilities vary, weighted load balancing can make a huge difference. In this setup, each server or consumer is assigned a weight based on its capacity. Faster machines handle more requests, while slower ones receive fewer.
6. Enhance Monitoring and Alerts
Prevention is better than a cure. Setting up comprehensive monitoring and alerts allows teams to identify uneven load issues before they cause outages.
Monitoring tools should track metrics such as CPU usage, memory consumption, response time, and queue length. Alerts can notify teams instantly if one server’s utilization suddenly spikes or if message lag increases.
Combining performance dashboards with automated alerting systems helps administrators take corrective action quickly—like redistributing traffic, scaling up resources, or tuning configurations.
7. Introduce DNS-Level Load Balancing
In large, geographically distributed systems, DNS-based load balancing can spread traffic across multiple data centers. It improves redundancy and ensures users connect to the nearest or least-loaded region.
If one data center fails or becomes overloaded, DNS routing redirects traffic to another location, maintaining uptime and performance for users worldwide.
8. Regularly Review Server Health and Connection Limits
Uneven distribution can also stem from server-level issues. Always verify that:
- Servers have enough CPU, memory, and bandwidth to handle the assigned traffic.
- Connection limits in the load balancer are set appropriately for expected workloads.
- Health checks accurately reflect server performance, ensuring that unhealthy nodes aren’t mistakenly assigned requests.
Routine infrastructure audits prevent unnoticed misconfigurations that cause imbalance.
Building a Balanced, Scalable System
Solving uneven load distribution isn’t just a one-time fix. It requires continuous tuning, observation, and adaptation. Here are a few long-term best practices:
- Combine load balancing with auto-scaling and real-time analytics to adapt instantly to changing demand.
- In Kafka or similar platforms, use automated partition reassignments based on lag metrics.
- Run periodic stress tests to identify weak points before they fail under real traffic.
- Infrastructure evolves, and so should load balancing configurations.
These proactive steps help maintain performance consistency even as systems grow.
Efficient traffic handling is a core aspect of cloud operations. Teams that already use managed cloud services can integrate load balancing, scaling, and monitoring under a unified management strategy. A well-structured cloud management plan ensures that load balancers, Kafka clusters, and compute instances all work together for optimal performance and cost efficiency.
To gain a deeper look into how professional management improves scalability, uptime, and resource utilization, check out our detailed guide on Cloud Management.
Conclusion
Uneven load distribution can silently degrade the performance of even the most advanced infrastructures. It can lead to inefficient resource usage and slower response times.
Addressing this challenge involves a mix of strategies: optimizing load balancer configurations, adopting lag-aware systems, enabling auto-scaling, and implementing intelligent monitoring. When done right, these steps ensure every component of a high-traffic system works in harmony, delivering fast, reliable, and uninterrupted service to users.
