



Just a couple of days back, Reddit went down for a few hours due to database errors. Some Redditors ranted in Twitter, some others joked about the downtime, but Reddit retained its loyal following. Now, imagine this happening to a brokerage site such as Wells Fargo, or an online store such as KMart.
Where there’s actual money involved, customers won’t be as loyal. They’d just take their business somewhere else, and think twice before returning.
Uptime is no longer a matter of choice for business websites. It’s now a core necessity to maintain market edge. To cater to this demand for high uptime, several cloud providers now offer “Mission critical cloud hosting” or “high availability hosting”, where the Service Level Agreement guarantees at least 99.9% server uptime.
In a previous post, we covered how oVirt was used to build a high ROI cloud hosting solution. Today, we’ll take a look at how high availability was configured in this oVirt cloud system.
See how our WHMCS oVirt plugin helps you!
How high availability works in oVirt
The oVirt cloud system is centrally managed by a server called oVirt engine. The oVirt engine keeps tabs on each server in the cloud system. If a server in the cloud (say Node 01) becomes unreachable, all virtual machines (aka VMs) running in that server would be transferred to other servers in the cloud. Users of those VMs would notice a small break in services, but everything would be back online in a couple of minutes.
This works because all operating system and application information of VMs are stored in a shared storage space accessible by all cloud servers. As you can see in the image, “Node 01”, “Node 02” and “Node 03” access the same “Shared storage”. So, VMs in “Node 01” can work equally well in “Node 02” or “Node 03” as long as the “Shared storage” is accessible from those servers.
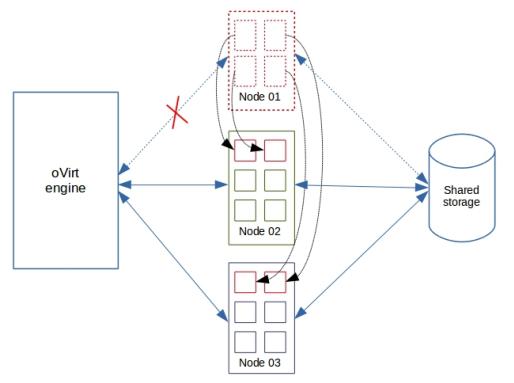
When the host “Node 01” fails, the VMs in “Node 01” is automatically migrated to “Node 02” and “Node 03”.
For high availability to work in oVirt, there are a few pre-conditions to be met. This includes a highly available shared storage device, power management on all servers, and surplus resources on all servers to accommodate VMs from other servers. Let’s take a look at them one by one.
Configuring shared storage
A shared storage is at the core of a highly available system. Unlike traditional dedicated servers, virtual machines (aka VMs) in a cloud store their operating system and applications in an external, high-speed storage device that sits outside the servers.
So, even if a VM’s host server goes down, the storage device remains online. It is then just a matter of starting the VM in another host server to bring the services back online.
In the cloud system we implemented, one of the shared storage devices we used was a RAID 10 array. All servers in the cloud system had access to this storage device. This made it possible for all VMs using that shared device to run off any host server in the cloud.
We chose a high-speed, redundant storage device such as RAID 10 array for this purpose because high availability would work only if the storage device remains online at all times.
[ Looking for custom plugins to manage your portals? Contact us to get tailor-made plugins to serve your business purposes. ]
Configuring power management on hosts
As mentioned earlier, oVirt is centrally managed by a server called oVirt engine. It is the oVirt engine’s job to detect if a cloud server has gone down, and initiate a VM transfer.
Now, consider a scenario where the network cable between oVirt engine and a cloud server is cut, but the cloud server is still connected to the shared storage device. The oVirt engine would think that the server is offline and create clones of VMs in that server on other cloud servers. This will essentially corrupt the data of all the VMs hosted on that cloud server.
To avoid this situation, oVirt REQUIRES that power management be accessible on all cloud servers for high availability to function. When oVirt detects a cloud server to be offline, first it’ll try to shutdown the server by turning off the power. ONLY IF the power shutdown is a success, will it attempt to put the VMs on another server.
So, before we enabled high availability in VMs, we configured power management for all servers in the cloud. It is done by navigating to “System” –> “Data Centers” –> “Clusters” –> “Hosts” –> “Edit”. The power management fields were filled in as shown here:
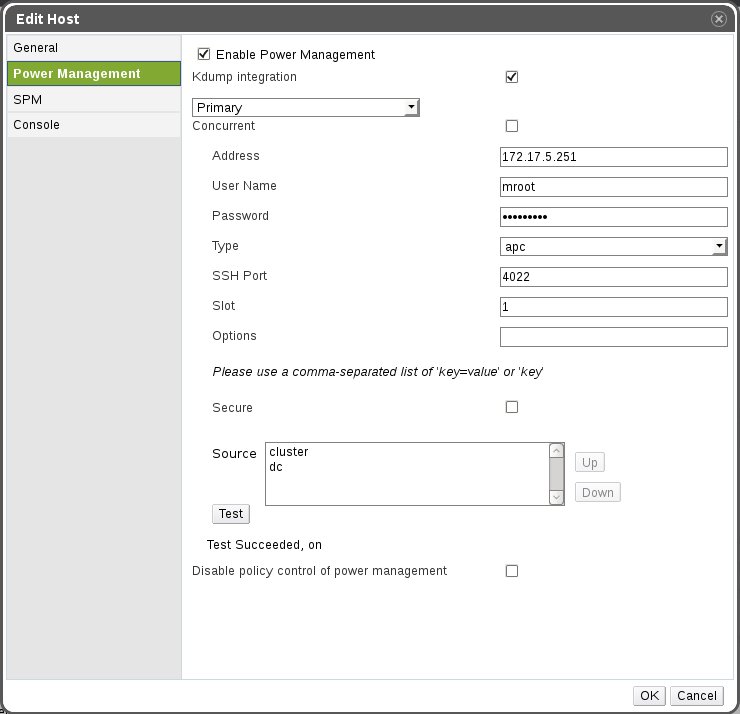
oVirt cloud systems host power management
Planning surplus resources to accommodate fail-over VMs
Let’s say there are 25 VMs in a cloud server called “Node 01”. These VMs would be allocated CPU and Memory resources that are carved from “Node 01’s” CPU and Memory capability. Now, let’s say the 25 VMs are allocated 50 GB of memory and 30 CPU cores in total. Then, for high availability to work, the rest of the servers in the cloud system should have a SURPLUS capability of 50 GB RAM and CPU cycles equaling 30 CPU cores.
For example, in the cloud system we implemented, we started off with 3 cloud servers which had 32 core CPUs and 64 GB RAM memory. The maximum resource that we could allocate on one server was 45 GB memory and 25 CPUs (with a bit of overselling). This allocation policy left ample space for VMs from one failed server to be evenly distributed over the other two.
[ Looking for the WHMCS plugin to manage your oVirt interface? Get our WHMCS plugin for oVirt management here. ]
Enabling high availability
Once the shared storage, power management and surplus resource planning was completed in the oVirt cloud system, the VMs were then ready to be enabled with “High Availability” fail-overs.
To do this, we enabled the “Highly Available” option under “System” –> “Data Centers” –> “Clusters” –> “VMs” –> “Edit” –> “High Availability”. Based on the hosting plan, the priority of fail-overs were selected in that interface. In case of a server failure, a VM marked as “High” priority would be started first, thereby minimizing downtime.
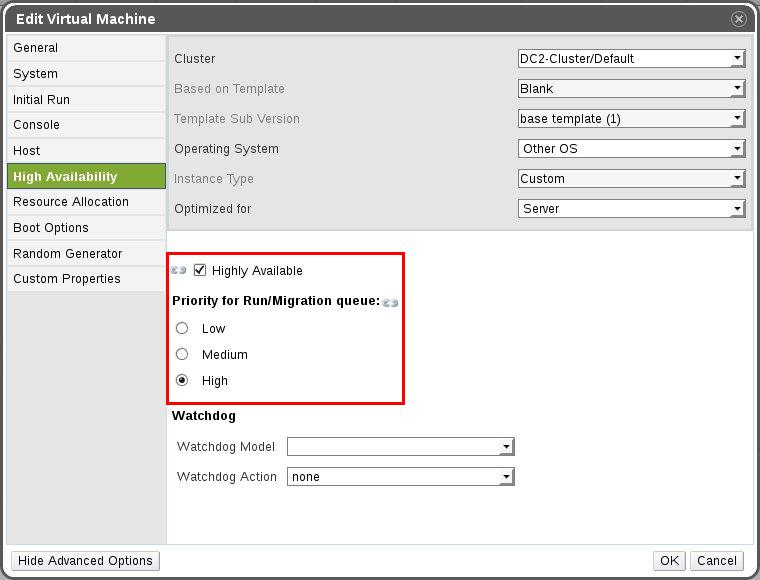
oVirt cloud – VM high availability configuration
High availability is a core feature in any cloud hosting solution. Here we’ve covered how high availability was implemented for an oVirt cloud system.
Bobcares helps cloud providers, data centers and web hosts deliver industry standard cloud services through custom configuration and preventive maintenance of server virtualization systems.

Hello,
I am trying to setup HA on Ovirt. I have followed your instructions but it is not working for me. Could you please offer some assistance.
Thanks.