




Want to Capture Screenshot of an Unreachable EC2 Windows Instance? We can help you.
An Amazon EC2 Windows instance might be unreachable due to network configuration, permissions, or high CPU use.
Here, at Bobcares, we assist our customers with several AWS queries as part of our AWS Support Services.
Today, let us see how we can capture a screenshot of the EC2 instance to check its status.
Capture Screenshot of an Unreachable EC2 Windows Instance
To identify why the connection attempt fails or times out we can use the Get Instance Screenshot feature.
It is possible to get a screenshot of an unreachable instance via the Amazon EC2 console or the AWS CLI.
The feature returns an image of the Windows desktop as if we were directly connected to the instance with a display monitor.
-
Log on screen (Ctrl+Alt+Delete)
If the log-on screen is unreachable it could be a problem with the network configuration or Windows Remote Desktop Services.
It can also be unresponsive if a process uses large amounts of CPU.
Network configuration:

Remote Desktop Services issues:
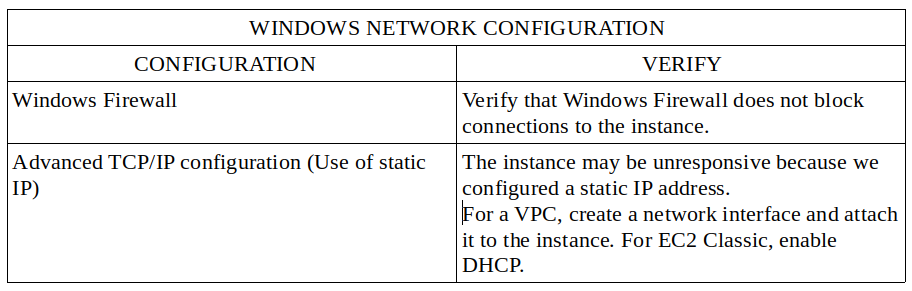
High CPU usage:
We can check the CPUUtilization (Maximum) metric on the instance using Amazon CloudWatch.
If it is a high number, we wait for the CPU to go down and try again.
Major causes of high CPU usage includes:
- Windows Update
- Security Software Scan
- Custom Startup Script
- Task Scheduler
-
Recovery console screen
If we do not set the bootstatuspolicy to ignoreallfailures, the OS may boot into the Recovery console.
To do so, our Support Techs recommend the following procedure:
- Firstly, we stop the unreachable instance.
- Then we create a snapshot of the root volume. It is attached to the instance as /dev/sda1.
- We detach the root volume from the unreachable instance, take a snapshot or create an AMI from it, and attach it to another instance in the same Availability Zone as a secondary volume.
- After that, we log in to the instance and run:
bcdedit /store Drive Letter:\boot\bcd /set {default} bootstatuspolicy ignoreallfailures - Finally, we reattach the volume to the unreachable instance and start the instance again.
-
Windows boot manager screen
Here, the OS experiences fatal corruption in the system file and/or the registry.
In such a case, we should recover the instance from a recent backup AMI or launch a replacement instance.
To get access data on the instance, we detach any root volumes from the unreachable instance, take a snapshot or create an AMI from them, and attach them to another instance in the same Availability Zone as a secondary volume.
-
Sysprep screen
If we do not use the EC2Config Service to call Sysprep or if the OS fails while running Sysprep we see the Sysprep screen.
Here, we can reset the password using EC2Rescue. Otherwise, we need to create a standardized AMI via Sysprep.
-
Getting ready screen
To verify the progress ring is spinning, we repeatedly refresh the Instance Console Screenshot Service.
If it spins, we wait for the OS to start up.
In addition, we can check the CPUUtilization metric on the instance with Amazon CloudWatch to see if the OS is active.
If the progress ring does not spin, the instance may be stuck at the boot process. In that case, we reboot the instance.
If this does not work, we recover the instance from a recent backup AMI or launch a replacement instance.
-
Windows Update screen
Generally, we wait for the update to finish. We should not reboot or stop the instance as it may cause data corruption during the update.
-
Chkdsk
Here, Windows is running the chkdsk system tool on the drive to verify file system integrity and fix logical file system errors. So, we wait for the process to complete.
[Stuck in between? We are here to assist you]
Conclusion
In short, we saw the methods our Support Techs use to capture screenshots of an unreachable EC2 Windows Instance.


0 Comments