




Learn more about HAProxy option redispatch from our experts. Our HAProxy Support team is here to help you with your questions and concerns.
HAProxy option Redispatch | Guide
In today’s digital age, high availability and fault tolerance for APIs is very important.
Many of our customers have had frustrating moments when an API goes down, leaving them with error messages and disruptions.
 To avoid these issues, we can use Postgres BDR. It is a multi-master database system that can reduce single points of failure.
To avoid these issues, we can use Postgres BDR. It is a multi-master database system that can reduce single points of failure.
Today, we are going to take a look at how to achieve fault tolerance while optimizing the efficiency of database caching with HAProxy.
When designing an API the goal is to minimize the risk of single points of failure. With Postgres BDR, we can establish two backend servers, each residing on a separate physical host and with its own database. This setup offers redundancy and resilience to our API infrastructure.
However, there’s a catch. It is better to keep most API requests on one server as long as it’s available. After all, it helps make database caching more efficient.
The standard way to achieve this in HAProxy is by designating one backend server as a “backup.” Here’s how it is usually configured:
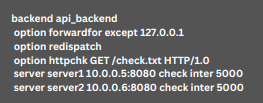
However, during software releases or updates, when we take down one server and then the other, clients may run into 503 errors. This occurs even if there is always at least one backend server available.
Identifying the Problem
Our experts investigated this issue further by creating a client-side Bash script to simulate continuous API requests:
while true; do curl http://host/api/v1/system/health; sleep 0.5; doneIn fact, during rolling updates across the servers, 1 or 2 requests consistently failed with HTTP 503 errors. This was unexpected since the “option redispatch” in HAProxy should have rerouted failed requests to the other server.
It turns out that this feature doesn’t work as expected when one backend is designated as a backup.
The Solution: Removing the Backup Option
Our experts then resolved the issue by removing the backup designation:
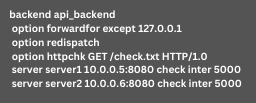
Now, the rolling updates will work smoothly without any HTTP 503 errors.
However, we do not want requests distributed evenly between both backends.
We can achieve this with a stick-table and a server1 with a higher weight:
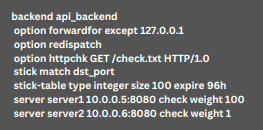
This offers successful rolling updates of the backend servers without any HTTP 503 errors.
In brief, achieving fault tolerance for our API infrastructure is key to providing a seamless user experience.
By carefully configuring HAProxy and Postgres BDR, we can minimize the risk of downtime and maintain efficient database caching.
With the stick-table and weighted load balancing technique, we have the tools to create a robust and resilient API environment that can withstand rolling updates and maintain uninterrupted service.
[Need assistance with a different issue? Our team is available 24/7.]
Conclusion
In brief, our Support Techs demonstrated how to use the HAproxy option redispatch to deal with rolling updates and maintain uninterrupted service.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.


0 Comments