




Let us take a closer look at how to Migrate using GCP Dataproc Serverless. With the support of our GCP support services at Bobcares we can give you a complete note on the process.
Why Migrate using GCP Dataproc Serverless?
Consider that we want to completely view the data without messing with SQL Server’s production settings. In this case, the best option is to move data from SQL Server to a trusted data warehouse, such as Google BigQuery.
Dataproc Templates, in conjunction with VertexAI notebook and Dataproc Serverless, provide a one-stop solution for directly moving data from MsSQL Database to GCP BigQuery.
Configuration: Migrate using GCP Dataproc Serverless: Important notes
- The information will automatically produce a list of tables.
- Alternatively, the user can provide a list of tables.
- The current primary key column name and partitioned read attributes are identified.
- If it crosses the threshold, then it will use the partition reads automatically.
- Divides migration into batches and migrates many tables concurrently.
- Notebook gives us the option of adding or overwriting data.
- If the table does not exist, Bigquery load will construct it.
Setup VertexAI Notebook:
Follow the steps given below to setup up the VertexAI notebook:
- Firstly, from the API Console, enable the following services in the GCP project. a: Compute Engine API b: Dataproc API c: Vertex-AI API d: Vertex Notebooks API
- After that, in Vertex AI Workbench, create a User-Managed Notebook.
- Finally, clone the Dataproc template repository using the GIT tab, as seen in the image below, or create a terminal session and clone using git clone.
git clone https://github.com/GoogleCloudPlatform/dataproc-templates.git - Open the
notebook from the folders tab, which is located in the path:MsSql-to-BigQuery-notebook.ipynb
.dataproc-templates/notebooks/mssql2bq
The next stages are implemented in the Python notebook with sequential marks for the convenience of the users.
Step 1: Install required packages
Some of the packages required to Migrate using GCP Dataproc Serverless must be installed separately because they are not accessible in the notebook, such as PySpark, JDK, and so on.
Step 2: Import Libraries:
The MSSQL and POSTGRES connection jars are required for this notebook. The notebook contains installation instructions.
Step 3: Set Google Cloud properties
Before starting the notebook, the following settings must be made:
Common Parameters
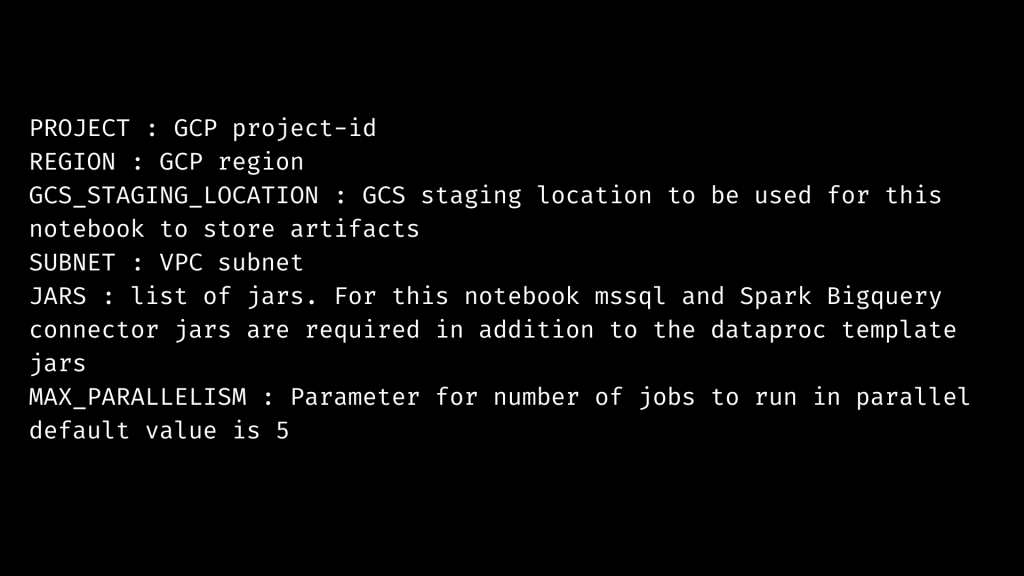
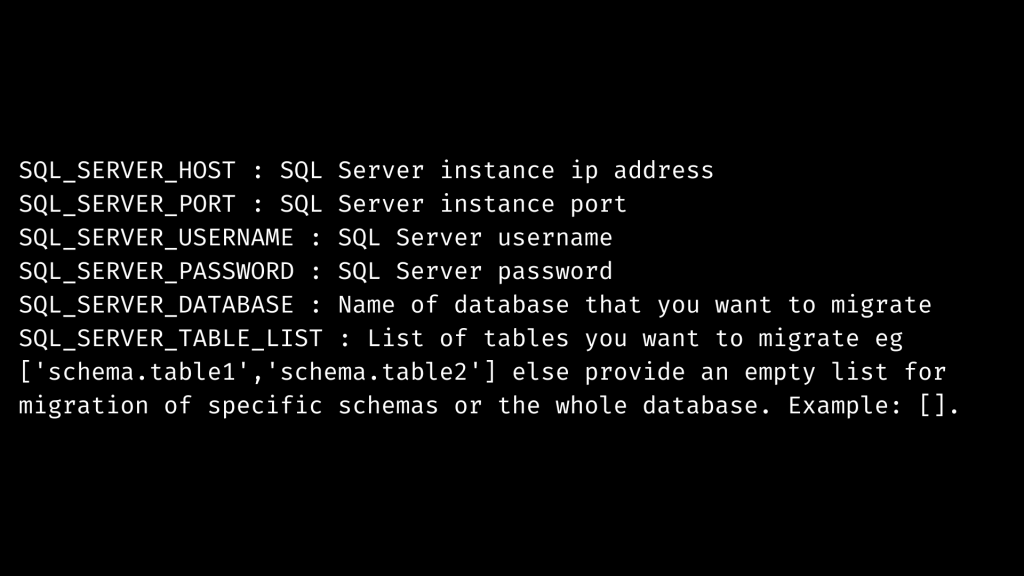
SQL Server Parameters to Migrate using GCP Dataproc Serverless

BigQuery Parameters

Step 4: Generate MsSQL Table List or MsSQL Schema List
After that This phase creates a list of tables or schema to migrate using GCP Dataproc Serverless. Consider that the SQL SERVER TABLE LIST / SQL SERVER SCHEMA LIST option is empty. In this case, all tables in the database are picked.
Step 5: Calculate Parallel Jobs for MsSQL to BigQuery
Based on the MAX PARALLELISM option, this phase creates parallel tasks for MsSQL to GCS migration and GCS to BigQuery migration. The number of MsSQL tables that will be parallelly transferred to BigQuery.
Step 6: Create JAR files and Upload to GCS
This step generates the necessary JAR files and uploads them to the GCS STAGING LOCATION setup in previous phases.
Step 7: Execute Pipeline to Migrate tables from MsSql to BigQuery
This phase will start the execution of the Vertex AI pipeline for MsSql table migration. Each task has its own pipeline link. We can also see the task executing in the Batches area of the Dataproc UI.
[Need assistance with similar queries? We are here to help]
Conclusion
To sum up we have now gone through how to Migrate using GCP Dataproc Serverless. With the support of our GCP support services at Bobcares, we have now gone through all of the setup processes.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.


0 Comments