




As they say, first impressions matter. Your next high value customer could be browsing your site right now.
What if your site fails to load? This scenario is not far from the truth for many websites, and very often it’s the database that fails.
Our Support Engineers support server infrastructure of several online businesses.
In our line of work we’ve seen Databases can fail due to resource limits (I/O, memory, CPU), file system errors, database table errors, or even hardware failures.
To avoid a downtime, it is important to setup high-availability systems for databases.
MySQL is by far the most popular database for web applications. Today, we’ll take a look at the top 7 solutions to enable high availability in MySQL database systems.
 1. Redundant devices to combat hardware failures
1. Redundant devices to combat hardware failures

Hardware failures is the number 1 reason for MySQL downtime*. This includes hard disk crashes, network card failures, power failure, etc.
The simplest way to avoid this pitfall is to use “two of everything” – use dual power units, dual network cards, RAID hard disks, etc. This will ensure that there’s no Single Point Of Failure (SPOF). Even if one device fails, another will keep the server running.
2. Shared storage with SAN and NAS
Using redundant hardware such as RAID keeps MySQL online even if one server component fails, but what if the whole server is cut off for some reason (like the rack fails)?
To combat that possibility, use a stand-by server that can come online if the main server fails. But it should be connected to a shared storage like SAN or NAS that sits outside the server.
So, if the main server goes down, a backup server can just connect to the shared storage, and continue serving database queries. However, the SAN/NAS device should be replicated to another device so as to avoid a Single Point Of Failure at storage level.

The main MySQL server shares the storage system with backup.
3. Storage replication using DRBD
In a server with RAID hard disks, if one disk fails, another with replicated data takes its place. But since both RAID disks are in the same server, the database will fail if the server itself goes down.
What if there’s a way to replicate a hard disk to another hard disk in a different server? That’s what Distributed Replicated Block Device (DRBD) achieves. It’s an open source Linux kernel module that allows data replication over the network.
When two servers are connected with DRBD, any update made to the database in one server is immediately replicated in the other server. So, in case the main server goes down, the backup server can be immediately brought online to continue the service.

DRBD keeps the hard disks of both the main and backup server identical, just like RAID.
Manually switching the database service to the backup server can cost a lot of time. As a solution, high availability switching tools such as Pacemaker can be used to automatically bring the backup server online.
[ You don’t have to be a MySQL expert to keep your sites always available. Hire experienced MySQL admins to manage your infrastructure. Plans start at $12.99/hour.]
4. MySQL replication to avoid single point failures
MySQL provides its own ways to deliver high availability. Most popular among that is replication. MySQL servers can communicate with other MySQL servers to keep themselves in sync with each other. This can be done in two ways:
- Master-Slave replication – In such a configuration, data can be written only to one MySQL server (known as Master), and it is copied by the other servers (known as Slaves).
- Master-Master replication – In a multi-master configuration, data can be written to any MySQL server in the replication group, and data is synched among each other.
Here’s a quick overview of the popular ways to do this.
a. Master-Slave replication
This is the most common type of MySQL replication where data is written to a single master server and the slave servers sync the data to their databases. With a bit of custom application coding, this system can be used to distribute database load across multiple servers.
If the master server goes down, one of the slaves can be promoted to become the master. This can be done either manually or using an automated script.
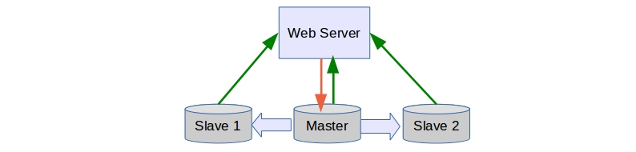
New updates are written only to master. Data is read from all nodes.
This system has a few disadvantages, notably,
- A slave server need to be “promoted” to become a master. Unless this process is automated using tools such as MHA, it won’t deliver true high availability.
- The slave servers are updated “asynchronously”, which means master does not check to confirm if slave is always up-to-date. This often means that the slave database is always a bit outdated. It can result in lost data in case of a Master server crash.
[ Click here to know how to setup MySQL master-slave replication. ]
b. Master-master replication
In a MySQL master-master replication system, each node is both a Master and Slave. Each server connects to others as Slave to get new updates, and *can* receive new updates. However, this system uses “asynchronous” replication, which means servers do not verify if others copied a new update. It can lead to inconsistent data in case of a downtime. So, in production systems, writes are sent to only one server.
This system however reduces the time to switch over in case of a downtime. The application server can just start writing to a different master, and the application downtime will be minimal.

Fail-over is easy, as each node is a master. The application just need to start writing to the new master.
This system in itself does not deliver high availability. A tool like Pacemaker should be used to monitor if the main server goes down, and if so, that server should be automatically shutdown (called STONITH), and write-access given to another master in the replication system.
c. Replication using MySQL-MHA
As discussed above, MySQL replication systems in itself do not provide high availability. It should be used along with tools that can promote a slave to a master (in case of master-slave replication), and grant write access to a new server (in case of master-master replication).
Master High Availability (MHA) is such tool that helps achieve HA in a MySQL replication system. MHA monitors the write-enabled Master server, and if the Master server goes down, it’ll quickly (with 10-30 secs) promote a Slave as the new master. It will also switch the IP of the old Master to the new Master, so that applications need not be re-configured.
d. Replication using MySQL-MMM
MySQL Master-Master (MMM) Replication Manager works much like MySQL-MHA, but it is specialized for multi-master replication systems. It can be configured to check the health of the current write-enabled Master, and in case of a failure, shut it down, and transfer its IP to another Master.
However, the real difference of MySQL-MMM from MySQL-MHA is that it can monitor the replication delay in different nodes, and prevent traffic going into nodes that have old data. This is useful in applications that allow real-time user interaction, like forums or chat rooms.
[ Don’t lose your customers to slow server. Our Support Engineers will keep your MySQL server optimized for best performance. Click here to know more. ]
5. MySQL clustering
As we’ve seen above, MySQL replication stores a full copy of the database in multiple servers. Each server will be independently able to function as the Master database server. This approach is not very scalable. As the database size increases, the capacity of EACH server in the replication group need to be increased.
MySQL cluster can be a good alternative for large databases, where data is split among many servers in such a way that a single server failure cannot cause a downtime. The data distribution is managed using a database format called “Network DataBase” or “NDB”.
Even if one NDB node fails, data can be retrieved from other nodes. Multiple MySQL servers can connect to an NDB cluster to read or write data. This way even if one MySQL server goes down, another can continue the service using a backup server.

Data is stored in a cluster of “data” servers using the NDB engine format.
NDB clusters are ideal for large business applications where new data is streamed in all the time (like market analytics). It handles writes very well, but if the majority of the database load is “read”, then NDB clusters will perform poorly. For this reason, NDB may not be a good choice for web applications.
6. Galera multi-master MySQL replication
As discussed earlier, MySQL’s multi-master replication method results in data conflicts when there’s a cut in network connection. Galera improved on MySQL’s multi-master replication system by introducing consistency checks.
In a Galera multi-master replication system, each server accepts new updates only if it can reach a majority of other servers. For eg. in a 5 server cluster, a server will accept new data only if it can talk to at least 2 others. If not, it will consider itself cut off from the network, and will shut down to avoid data corruption.
This feature and many other such tweaks makes Galera replication better suited for mission critical applications than native MySQL replication.

Galera removes the data inconsistency and lag issues in MySQL master-master replication.
MYSQL DOWN? CLICK HERE TO RESCUE YOUR SERVER NOW!
7. Percona XtraDB Cluster
Native MySQL replication methods have performance penalties and are known to produce inconsistent data. Percona XtraDB Cluster (PXC) is an alternative to native MySQL replication that fixes all those issues.
PXC uses the fail-safe multi-master replication technology from Galera, and improves on the InnoDB engine of MySQL to produce a MySQL compatible replication system, which is both fast and reliable.
A PXC cluster consists of minimum 3 database nodes which are always in sync. Data can be read from or written to any of these nodes. The ideal database service architecture is to channel all database queries through a load balancer, so that database load will be distributed evenly.

[ Click here to know how to setup a Percona XtraDB Cluster (PXC). ]
Summary
Improving the uptime of the database can significantly increase your website uptime. Here we’ve gone through the top 7 solutions to improve MySQL uptime. The right solution for your infrastructure depends on various factors such as database performance, ease of management, etc.
Bobcares helps business websites of all sizes achieve world-class performance and uptime, using tried and tested website architectures. If you’d like to know how to make your website more reliable, we’d be happy to talk to you.



0 Comments