




A website suddenly goes offline. The server is un-responsive. A server reboot is attempted, but the server fails to come back online.
This is typical of the way a server crash would unfold. As a server management company, we’ve often seen such issues with dedicated servers, however, recently we’ve started seeing such issues in cloud systems as well. People tend to associate cloud systems with stability, but even cloud system hardware and software are susceptible to failures.
When such server (or cloud instance) failures happen, potentially several thousands of users would be cut off from their business transactions. So, for us, server downtimes are high priority issues, which we resolve as soon as possible.
Recently our team fixed a cloud instance downtime as part of our dedicated support services. A US based cloud service provider used our services to manage their OnApp cloud management systems and to deliver 24/7 technical support. As part of technical support, we help server instance owners recover from service downtimes, and custom configure their servers.
One day, an emergency server recovery request was logged by a website owner who used a server instance on the OnApp system. The server instance had failed to respond, and even after repeated reboot requests, the server instance stayed offline.
Our team quickly got on the case, and as the first step, analyzed the OnApp system logs. We saw a log entry related to the customer’s server instance:
Fatal: OnApp::Actions::Fatal Storage API Call failed: {"result"=>"FAILURE", "error"=>"onappstore onlineVDisk fhxishv3q51grj failed on frontend 677973259 with error map: [('677973259', u'Failed to find any active members in sync')] and optional error: API call failed for a subset of nodes. Failures: [('677973259', u'Failed to find any active members in sync')]"}
This log showed that customer’s server instance (with the ID fhxishv3q51grj) had an error in its storage device. To fix this error, we had to:
This is the story of how we did it.
Tracing error “onappstore onlineVDisk [] failed”
Before we get into the error details, let’s get a bit of background.
OnApp allows aggregating different storage devices (such as hard disks, SSD drives, SAS, etc.) to form a single virtual storage system called “Integrated Data Store”. In this case, it looked like the Data Store the website was hosted on, developed an error which was preventing the server instance from booting up.
To do that, we needed to identify the Data Store linked to the server instance. So, we looked further into the system logs and found this entry:
Running: Storage API Call: PUT 10.0.0.51:8080/is/Datastore/pmjl4tghe52pzq/VDisk/fhxishv3q51grj "{\"state\":2,\"frontend_uuid\":\"677973259\"}"
It showed that the Data Store being used was pmjl4tghe52pzq.
Now, to get the exact reason why the Data Store was showing errors, we needed to locate the “Node” in which the website was hosted. OnApp divides each Data Store into several “Nodes” on which several server instances would be hosted.
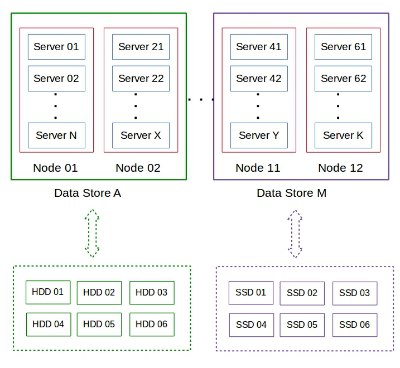
How OnApp stores data in Nodes and DataStores.
A quick look at the “Nodes” list in the OnApp admin panel showed the Node ID of the affected server instance as 3843437812. Once we had the Node ID, we logged into that node to check what could be wrong with the disks. We saw several Input/Output errors related to XFS file system in the Node logs:
XFS (xvda): metadata I/O error: block 0x22eb087a ("xlog_iodone") error 5 buf count 12288 XFS (xvda): xfs_log_force: error 5 returned. -- [xvda]
This showed that the XFS file system in one of the hard disks in the node 3843437812 was corrupted and needed to be repaired.
Fixing the file system corruption
OnApp stores the data of different server instances in storage areas called “Nodes”. Server instances run on huge servers called Hypervisors, and storage “Nodes” are linked to Hypervisors so that each server instance can access their data. In this case, Node 3843437812 was linked to a Hypervisor called “Xen Kappa 02“.
In order to fix the XFS file system error, the corrupted hard disk in Node 3843437812 had to be first de-linked from Xen Kappa 02. For that, we logged in to Xen Kappa 02, and issued a
diskhotplug unassignThen, we fixed the XFS error with the command
xfs_repair /dev/sdcdiskhotplug assignEverything worked perfectly fine. 🙂
Bobcares helps data centers, web hosts and other online businesses deliver reliable, secure services through 24/7 technical support and server management.


0 Comments