




Learn more about Graphical Frontend for Borg backup Ubuntu. Our Server Management Support team is here to help you with your questions and concerns.
Graphical Frontend for Borg backup Ubuntu
BorgBackup, also known as Borg, is a deduplicating backup program. It offers efficient and secure ways to back up our data.
It is a command-line tool. However, some users may not be comfortable using the collamd line tool.
A graphical frontend for BorgBackup on Ubuntu will make it more accessible to users.
Instead of typing commands in a terminal, it will let users perform backup and restore operations using a graphical user interface (GUI).
In fact, most of our customers agree that having a GUI client like Vorta makes life a lot easier when working with borg.
Vorta is a GUI desktop client for BorgBackup. With it, we can easily integrate the Borg application into our favorite desktop environment. There is no longer a need to remember the commands. Users can simplify tasks effortlessly with a user-friendly graphical interface.
Vorta employs Borg as its backend, enabling users to effortlessly create encrypted, deduplicated, and compressed backups with just a few clicks. Whether storing data locally, remotely, on our own system or utilizing BorgBase hosting service for cloud backup, Vorta offers versatile backup options.
In fact, we can explore the archives and restore files from one place. You can also create multiple profiles to group source folders, backup destinations and schedules.
Vorta is compatible with any system supporting Qt and Borg. It offers a free, open-source, and multi-platform application. While it seamlessly functions on Linux and macOS, Windows support is still pending.
Without delay, let’s proceed to explore the installation of Vorta and the steps involved in backing up and restoring files using this application.
Here is an overview of what we will be going through:
- Install Vorta on Linux
- Establish a Backup Repository
- Select Source Data
- Access Backup List
- Rename Archives Effortlessly
- Prune Archives
- Extract Data from Archives
- Delete an Archive
- Schedule Your Backups
- Manage Profiles: Export and Import
Install Vorta In Linux
Our experts recommend using the python package manager PiP to install Vorta regardless of our Linux distribution.
We can use any one of these commands to install Vorta as per our version of PiP:
$ pip install vortaOr,
$ pip3 install vortaFurthermore, we can install Vorta through flatpak.
$ flatpak install flathub com.borgbase.Vorta
$ flatpak run com.borgbase.VortaAdditionally, Vorta comes pre-packaged for popular Linux operating systems. So, we can easily graphical frontend for Borg backup in Ubuntu with the default package managers.
- For Debian/Ubuntu:
$ sudo apt install vorta - On Fedora and other RPM-based systems:
Here, we can install Vorta from the copr repository as seen here:
$ sudo dnf copr enable luminoso/vorta
$ sudo dnf install vorta
Additionally, Vorta is available in AUR. In other words, we can install Vorta in Arch Linux, as well as its derivatives like Manjaro Linux and EndeavourOS, via AURH helper tools like Yay or Paru.
$ paru -S vortaOr,
$ yay -S vortaOr,
$ sudo eopkg it vortaEstablish a Backup Repository
Before we begin, let’s go over the term we will be using here. Archives will be denoted as snapshots, while the storage locations designated for these snapshots are termed repositories.
- To begin with, head to Repository under the Repository tab and click Initialize New Repository.
- This will open up a new window where we have to select a backup repository location as well as a passphrase and encryption type.
- Now, we have to choose a remote repository (username@hostname:/path/to/repo) rather than the local repository path.
- At this point we have to remember the passphrase. Each time we want to access this repository, we have to enter this passphrase. Alternatively, we can skip setting passphrase.
- Now, click the Advanced tab to set the encryption type for our repository. Although we can opt for “None”, it is not recommended.
- Furthermore, we can select the type of compression algorithm to use for the archived data.
Select Source Data
Now, it is time to choose the Source data. First, head to the Sources tab. Here, we will have several options to choose from. work with.
We can opt to add or remove directories or files. Furthermore, we can create an exclude pattern in its respective tab. In this case, the matched pattern will skip the file or directory to be skipped when we run.
Once we add the directories or files to be used as the source directory, it is time to click Start backup.
After the backup is completed we will get backup stats as well as status messages like the one seen below:
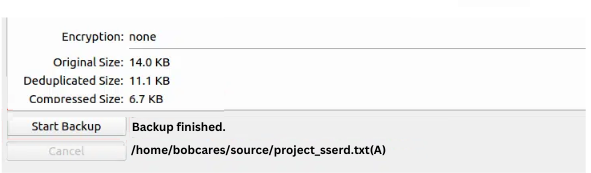
Access Backup List
If we have taken several snapshots for a repository, we can access a list of these snapshots under the “Archives” section.
Furthermore, the archive is saved with the following name format by default.
{hostname}-{now:%Y-%m-%d-%H%M%S}”
It will be easy to find the backup date and time from the archive name or through the Date column.
However, before we go about restoring data from these archives, it is important to know which archive contains the directory or file that we want to restore and what version is stored. We can use the “Diff” section to compare the two archives before making a decision.
The Diff option is under the Archives tab as seen here:
![]()
We can choose the two archives we want to compare at this point.
After selecting the two archives we want to compare, we have to click Diff. Then, we will be taken to a window where the differences will be displayed. We can make a decision based on this information.
Rename Archives Effortlessly
Although archives are named according to a specific format by default, we can opt to rename them as well. This involves choosing an archive from the archives tab and click “Rename” from the menu.
Then, we have to enter a new name for the archive and click “OK”.
Prune Archives
The Prune option lets us keep a fixed number of archives and remove the rest. Based on how we set up our backup(Yearly, Monthly, Daily, Weekly, Hourly), we can choose to retain N number of copies.
Furthermore, we can also use prune on archives that start with certain prefixes. In this case, we have to set what should be the prefix of our archive under “Prune Prefix”.
Extract Data from Archives
Did you know we have two ways to restore data using Vorta?
We can opt for either “Extract” or the “Mount” option.
The former extracts the data to the given directory while the latter mounts the archive as the file system and we can manually copy the data.
If we are using the Extract option, we have to choose the archive and click Extract. This will open a window where we have to select the data that needs to be extracted. Then, we have to select the destination directory.
On the other hand, when we use the Mount option, we have to choose the archive and click Mount.
Then, we have to select the destination directory where we want the archive to be mounted. This lets us copy the data where we want in the file system.
Furthermore, we can unmount the archive by selecting the “Unmount” option.
Delete An Archive
We can also easily delete an archive from the repository as and when needed by choosing the archive and clicking Delete.
Schedule Your Backups
Finally, to make taking backups easier, Vorta has a built-in scheduler. We can use it to automate our backups.
We can set it up to run as per our needs. Furthermore, we can also opt to “prune” old archives after running each automatic backup.
Manage Profiles: Export and Import
If you are looking for a way to export a profile, Vorta has your back. The profile is saved as a .json file which can be imported if required to retain all the settings.
First, we have to select the export icon as seen below, enter the name for the json file, and save it.

At this point, we can import the json file to keep the profile settings.
When it is time to import the file, we have to click “Import from file” and select the json file we exported.
Now all our settings and backup data will be imported.
[Need assistance with a different issue? Our team is available 24/7.]
Conclusion
At the end of the day, our Support Experts demonstrated how to install and use Vorta in Linux.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.


0 Comments