




Stuck with the Kubernetes Cluster: Status of Node is NotReady error? We can help you.
Generally, with this error, we will have an unstable cluster.
As part of our Server Management Services, we assist our customers with several Kubernetes queries.
Today, let us see how we can fix this error quickly.
Kubernetes Cluster: Status of Node is NotReady
Recently, one of our customers came to us regarding this query. For him, the status of the node was returning as “NotReady”. In such a case, the cluster is unstable.
For example,
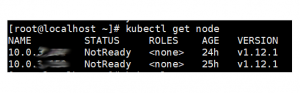
backend7-123:~ # kubectl get nodes
kubectl describe node 10.0.xx.xx
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk Unknown Tue, 29 Jan 2019 11:06:05 +0800 Tue, 29 Jan 2019 11:06:45 +0800 NodeStatusUnknown Kubelet stopped posting node status.
MemoryPressure Unknown Tue, 29 Jan 2019 11:06:05 +0800 Tue, 29 Jan 2019 11:06:45 +0800 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Tue, 29 Jan 2019 11:06:05 +0800 Tue, 29 Jan 2019 11:06:45 +0800 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure False Tue, 29 Jan 2019 11:06:05 +0800 Mon, 28 Jan 2019 15:11:01 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready Unknown Tue, 29 Jan 2019 11:06:05 +0800 Tue, 29 Jan 2019 11:06:45 +0800 NodeStatusUnknown Kubelet stopped posting node status.
Here, we can see that the output displays, ‘Kubelet stopped posting node status’.
Then, we proceed to review the node104 node.
tail /var/log/messagesThis will return us results showing, not found.
How to solve this?
Moving ahead, let us see how our Support Techs fix this error for our customers.
-
Restart each component in the node
systemctl daemon-reload systemctl restart docker systemctl restart kubelet systemctl restart kube-proxy
Then we run the below command to view the operation of each component. In addition, we pay attention to see if it is the current time of the restart.
ps -ef |grep kube
Suppose the kubelet hasn’t started yet. This means the node is not checked in the master.
-
View firewall issues
systemctl status firewalld ----------carried out systemctl stop firewalld systemctl enable firewalld
We need to make sure the firewall is off
systemctl status firewalld
Finally, on the LB load balancing server, check the running log to monitor the running of k8s in real-time:
tail /var/log/nginx/k8s-access.log -f
Eventually, we can see the fix.
[Need help with the error? We’d be happy to assist]
Conclusion
In short, we saw how our Support Techs fix the Kubernetes Cluster error.


0 Comments