




Kubernetes Horizontal Pod Autoscaler automatically updates a workload resource in order to scale the workload to meet demand.
In accordance with our Server Management service, Bobcares answers all queries, no matter how insignificant.
Let’s look more closely at the Kubernetes Horizontal Pod Autoscaler.
Kubernetes Horizontal POD Autoscaler
Horizontal scaling is the process where it adds more Pods as the load increases. Vertical scaling, which for Kubernetes would entail allocating more resources to the Pods that are already active for the workload, is different from this.
The Horizontal Pod Autoscaler instructs the workload resource to scale back down if the load decreases and the number of Pods is greater than the configured minimum. Horizontal pod autoscaling has no effect on non-scalable objects.
The horizontal pod autoscaler uses both a controller and a Kubernetes API resource. The resource dictates how the controller will act. The Kubernetes control plane’s horizontal pod autoscaling controller periodically modifies the target’s desired scale to correspond to observed metrics like average CPU utilisation, average memory utilisation, or any other custom metric we specify.
The execution of a horizontal pod autoscaler
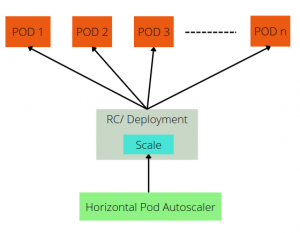
The Horizontal Pod Autoscaler controls both the scale of a Deployment and its Replica Set. Kubernetes implements horizontal pod autoscaling as an ad hoc control loop. The default interval is 15 seconds and is set by the
--horizontal-pod-autoscaler-sync-periodkube-controller-managerThe controller manager runs a query on the resource utilisation against the metrics listed in each Horizontal Pod Autoscaler definition once per period. The controller manager locates the target resource defined by the
scaleTargetRef.spec.selectorIt is common practise to configure Horizontal Pod Autoscaler to retrieve metrics from aggregated APIs. The
metrics.k8s.io APIAlgorithm information
The ratio between the desired and current metric values is the foundation upon which the Horizontal Pod Autoscaler controller functions. The
currentMetricValuetargetAverageValuetargetAverageUtilizationThe control panel also takes into account whether any metrics are missing. Then it considers how many Pods are Ready before determining the tolerance and choosing the final values. We discard all failed pods. And it ignores all pods with a deletion timestamp set. It saves a particular Pod for later if it is missing metrics.
Utilizing pods with missing metrics, the final scaling amount will change. When scaling on CPU, any pods that have not yet ready or whose most recent metric point occurred before they were ready are also put on hold.
A Horizontal Pod Autoscaler performs this calculation for each of the metrics specified in it, and then chooses the replica count with the highest replica count as the desired replica count.
If any of these metrics can’t convert into the desired replica count, it skip the scaling. And the metrics that are retrievable point to a reduction. This shows that the HPA is still capable of scaling up in the event that one or more metrics produce Replicas that desire to be higher than the current value.
API Object
The Kubernetes autoscaling API group contains an API resource called the Horizontal Pod Autoscaler. The
autoscaling/v2autoscaling/v1Workload scale stability
Due to the dynamic nature of the metrics considered, it is possible that the number of replicas keeps changing frequently when managing the scale of a group of replicas using the Horizontal Pod Autoscaler. This is also referred to as flapping or thrashing. It resembles the cybernetics concept of hysteresis.
Rolling update with autoscaling
We can apply a rolling update to a Deployment using Kubernetes. In that case, we manage the underlying Replica Sets through the Deployment. We bind a Horizontal Pod Autoscaler to a single Deployment when configuring autoscaling for a Deployment. The Horizontal Pod Autoscaler manages the Deployment’s replicas field.
The deployment controller must configure the replicas of the underlying Replica Sets to add up to a certain number both during and after the rollout. A StatefulSet that has an autoscaled number of replicas manages its collection of Pods directly when we perform a rolling update on the StatefulSet.
[Looking for a solution to another query? We are just a click away.]
Conclusion
In conclusion, Kubernetes enables rolling updates for Deployments. Additionally, Kubernetes implements horizontal pod autoscaling as an ad hoc control loop. Our Support team provide a thorough explanation of the horizontal POD Autoscaler in Kubernetes.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.


0 Comments